개요
오늘은 Redis의 자료구조 중에 List와 Sorted Set에 대해서 알아보려고 한다.
List
레디스 List는 문자열 값들의 linked list이다.
Redis lists are linked lists of string values.
list를 구현하는 방법은 2가지가 있다.
- Array
- Linked List
그리고, Array와 Linked List는 요소를 삽입 및 삭제, 요소 탐색간에 시간복잡도의 차이가 있다.
Array와 Linked List의 작업별 시간복잡도는 아래와 같다.

시간복잡도의 차이가 나는 이유
1. 요소의 삽입
먼저, 특정 요소를 중간에 삽입하는 경우에 대해서 알아보자.
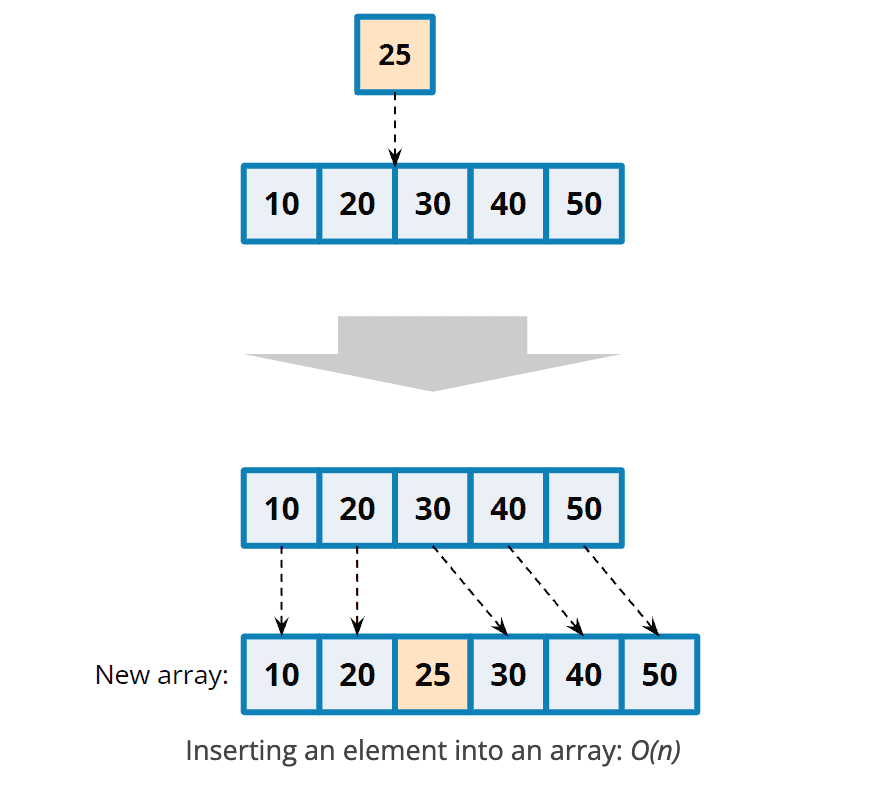
Array 중간에 25라는 새로운 요소를 삽입하는 경우에는, 삽입하고자 하는 위치 뒤에 있는 모든 요소들을 한칸씩 뒤로 미루어 줘야하기 때문에, O(n)의 시간 복잡도를 가진다.
반면에, Linked List의 경우에는 삽입하고자 하는 직전 노드의 next의 값과, 새로운 노드의 next의 값만 변경해주면 삽입이 완료되므로 , O(1)의 시간복잡도를 가진다.

잠시 자료구조로 빠졌지만, redis로 다시 돌아와서 redis에서 list를 Linked List로 구현한 이유에 대해서 생각해보면 다음과 같다. (= list를 linked list로 구현했을시에 장점)
- Time(길이가 10만인 list인 리스트에 새로운 요소 추가) = Time(길이가 10인 list인 리스트에 새로운 요소 추가)
- Java에서 Queue를 구현할때 LinkedList로 하는 이유
- 일정한 길이를 일정한 시간 안에 유지할 수 있다.
- SNS 피드에 최신 순으로 올라온글에 100개만 유지시키는 경우 (LTRIM을 활용)
2. 요소의 탐색
List에서 3번째에 위치한 요소를 탐색하고 한다고 생각해보자. Array의 경우에는 Array 첫번째에 위치한 요소의 주소값이 곧 Array의 시작값이므로 자료형의 byte수를 참고하여 계산하면 바로, 3번째 요소의 주소값을 찾을 수 있다. 따라서 시간 복잡도는 O(1)이 된다.

반면에, Liked List의 경우는 그렇지 않다. Linked List의 각 노드들은 다음 노드의 주소값만 (Singly Linked List의 경우) 알뿐이다. 따라서 3번째 요소를 탐색하기 위해서는 3개의 노드를 다 뒤져야만 한다. 따라서 LinkedList에서의 탐색 작업의 worst time complexity는 O(n)이 된다.

다시 redis로 돌아와보면 redis는 list를 linked list로 구현했기 때문에 요구사항을 고려해보았을때, 길이가 긴 data 중간에 빠르게 접근하려면 Sorted Sets을 사용해야많다.
그렇지 않다면, 위에서 알아본대로 배열 중간에 위치한 요소에 인덱스로 접근시 O(n) 소요가 될 것이다.
Sorted sets
Sorted sets은 “score”를 기준으로 정렬된 고유한(=중복이 없는) 문자열의 모음이다.
정렬 기준
- A.score가 > B.score인 경우 A > B
- A.score == B.score인 경우 A 문자열이 B 문자열보다 사전적으로 더 크면 A > B
- Sorted Set에 중복 값은 없다.
구현체
Sorted sets은 skip list와 해시테이블을 포함하는 dual-ported 자료구조로 구현되었다.고 redis 공식문서에 적혀있다.
Sorted sets are implemented via a dual-ported data structure containing both a skip list and a hash table, so every time we add an element Redis performs an O(log(N)) operation.
먼저 해시테이블은 임의의 해시 함수에 요소를 대입하여 나온 결과 값을 기준으로 요소들을 위치시킨다.

Skip List
Skip List는 말그대로 일정한 node들을 생략,Skip하는 노드들을 위치시켜 Linked List의 단점이었던 탐색시간을
O(n)에서 O(log(n))까지 감소시킬 수 있다. 아래 그림을 통해 이것이 어떻게 가능한지 알아보자.
가장 먼저 일반적인 Linked List의 구조이다.

그리고 두번째 그림은 1개의 node를 스킵하는 Skip List이다.
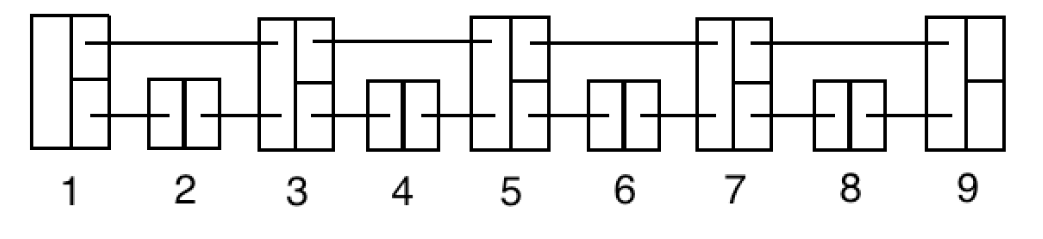

위의 과정들을 n번 반복하면 탐색 속도는 O(log(n))으로 수렴한다.
💡레벨을 1단계 추가할 때마다 2^n 개의 노드만큼 skip하여 탐색할 수 있다. 16레밸을 갖추면 65,536번째 노드와 바로 비교가능하다.
하지만 list 중간에 위치한 임의의 데이터를 삭제할 경우 위와 같은 모양을 유지 할 수 없다. 따라서, 특정 노드에 연결된 pointer의 개수를 확률적으로 정해두는 방식으로 보통 이 문제를 해결한다. (redis에서는 1/4확률 사용)
3/4 확률로 레벨 1
1/4*3/4 확률로 레벨 2
1/41/43/4 확률로 레벨 3
…반복

Reference
'개발' 카테고리의 다른 글
| Ajax에 대해서 알아보자 (0) | 2025.03.02 |
|---|---|
| 간략하게 알아보는 docker 개념 (0) | 2025.02.16 |
| SOLID Principle 알아보기 - 두번째 (0) | 2025.01.05 |
| JVM 두번째 글 - Heap 메모리 구조에 대하여 (0) | 2024.12.22 |
| SOLID Principle 알아보기 - 첫번째 (0) | 2024.11.24 |



