개요
DB 사용시 반드시 사용하게 되는 인덱스에 대해서 알아보려고 한다.
인덱스란?
인덱스는 데이터 저장, 수정, 삭제에 대한 성능을 희생시켜 탐색에 대한 성능을 대폭 상승하는 방식
그리고 인덱스는 B-Tree(Balanced Tree)를 사용한다.
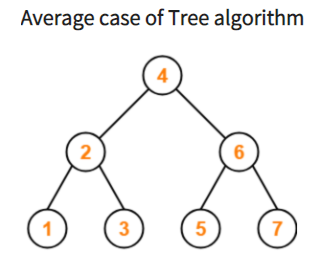

트리의 노드가 편향되는 worst case를 방지하기 위해서 우리는 밸런스 트리(Balanced Tree)를 이용할 수 있다
밸런스 트리?
트리의 노드가 한 방향으로 쏠리지 않도록, 노드 삽입 및 삭제 시 특정 규칙에 맞게 재 정렬되어 왼쪽과 오른쪽 자식 양쪽 수의 밸런스를 유지하는 트리이다. 항상 양쪽 자식의 밸런스를 유지하므로, 무조건 O(logN)의 시간 복잡도를 가지게 된다.
다만 재정렬되는 작업으로 인해 노드 삽입 및 삭제 시 일반적인 트리보다 성능이 떨어지게 된다. 그러므로 밸런스 트리는 삽입/삭제의 성능을 희생하고 탐색에 대한 성능을 높였다고 볼 수 있다. 밸런스 트리는 대표적으로 RedBlack-Tree, B-Tree가 있다.
"왜 하필 B-Tree지?" "탐색 시간이 O(logN)인 자료구조나 알고리즘은 다른 것들도 많지 않나?"
왜 B-Tree지?
"해시 테이블은 O(1)인데, 그러면 차라리 해시 테이블을 쓰는 게 더 빠르지 않나?"
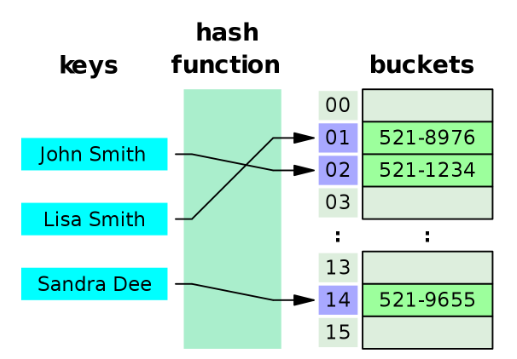
해시 테이블은 해시 함수를 통해 나온 해시 값을 이용하여 저장된 메모리 공간에 한 번에 접근을 하기 때문에 O(1)이라는 시간 복잡도를 가진다. (물론 해시 충돌 등으로 최악의 경우에 O(N)이 될 수 있지만, 평균적으로는 O(1)으로 볼 수 있다)
그러나 이는 온전히 '단 하나의 데이터를 탐색하는 시간' 에만 O(1)이다. 예를 들어 1,2,3,4,5가 저장되어 있는 해시 테이블에서 3이라는 데이터를 찾을 때에만 O(1)이라는 것이다.
'그게 무엇이 문제이냐'라고 생각한다면 잠깐 이 부분을 놓쳤을 것이다.
우리는 DB에서 등호(=) 뿐 아니라 부등호(<, >)도 사용할 수 있다는 것을.
모든 값이 정렬되어있지 않으므로, 해시 테이블에서는 특정 기준보다 크거나 작은 값을 찾을 수 없다. 굳이 찾으려면 찾을 수는 있지만 O(1)의 시간 복잡도를 보장할 수 없고 매우 비효율적이다.
그렇기에 기준 값보다 크거나 작은 요소들을 항상 탐색할 수 있어야 하는 DB 인덱스 용도로 해시 테이블은 어울리지 않는 자료구조인 것이다.
"그러면 밸런스 트리 중 B-Tree 말고도 RedBlack-Tree로도 사용할 수 있는 것 아닌가?"


이처럼, 위 두 개의 트리는 항상 좌, 우 자식노드 개수의 밸런스를 유지하므로 최악의 경우에도 무조건 탐색 시간이 O(logN)을 가지게 된다. 이것만 보면 B-Tree 뿐 아니라, RedBlack-Tree도 DB 인덱스로 사용하기에는 큰 문제가 없어 보인다.
그러면 도대체 왜 RedBlack-Tree는 DB 인덱스로 선택받지 못한 것일까.
RedBlack-Tree와 B-Tree의 차이는 무엇일까?
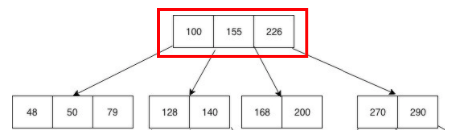
위의 사진만 봐도 알 수 있듯이, 이 둘의 가장 큰 차이는 '하나의 노드가 가지는 데이터 개수'이다. RedBlack-Tree는 무조건 하나의 노드에 하나의 데이터 요소만을, B-Tree는 하나의 노드에 여러 개의 데이터 요소를 저장한다.
표시한 부분을 한번 보자. 마치 배열처럼 정렬이 되어있다. 맞다. 배열이다. 실제 메모리 상에 차례대로 저장이 되어있는 것이다. 같은 노드 공간의 데이터들끼리 굳이 자식 노드처럼 참조 포인터 값으로 접근할 필요가 없다.
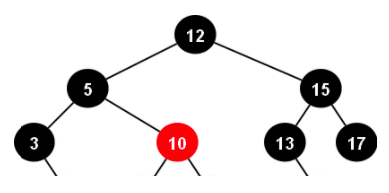
RedBlack-Tree는 B-Tree와 다르게 각 노드마다 무조건 하나의 데이터만 가지게 되므로 모든 데이터를 접근할 때 무조건 참조 포인터로 접근을 하게 된다
이론적 → 둘다, 시간 복잡도는O(logN)
물리적 → 배열 접근 Win!
"참조 포인터가 문제라면 그냥 참조 요소 자체가 없는 배열을 쓰면 되지 않나?"
하지만 배열이 B-Tree보다 빠른 것은 '탐색'뿐이다. 배열 내에서 데이터 저장, 삭제가 일어나는 순간 B-Tree보다 훨씬 비효율적인 성능이 발생하게 된다.
“배열에서 삽입,삭제가 느리다면, 포인터 LinkedList를 사용하면 되지 않나요?”
문제점은??!
LinkedList에 Index Number라는 개념이 있던가?
또한 각 요소에 Index Number 정보들을 추가로 가지고 있다 해도, 그 Index Number로 해당 요소로 바로 접근을 할 수 있는가?참조 포인터로만 이루어져 있는 LinkedList에서는 이러한 일고리즘을 적용할 수 없다.
탐색을 무조건 제일 앞 부분인 'HEAD'부터 시작해야 하는 LinkedList로서는, DB-Index로 사용하기엔 매우 비효율적인 자료구조가 되는 셈인 것이다.
'개발' 카테고리의 다른 글
| 람다에 대해서 알아보자 - 1편 (탄생배경, 변수캡쳐, 함수타입) (0) | 2025.11.26 |
|---|---|
| 싱글톤 패턴 (0) | 2025.03.30 |
| Ajax에 대해서 알아보자 (0) | 2025.03.02 |
| 간략하게 알아보는 docker 개념 (0) | 2025.02.16 |
| Redis의 자료구조 (List, Sorted Set) (0) | 2025.01.19 |

