Kotlin in Action을 읽다보면 6장 "컬렉션과 시퀀스"에서 '컬렉션에 대한 함수형 API'라는 제목을 마주하게 됩니다. 단순히 유틸리티 함수라고 부르지 않고 굳이 '함수형'이라는 수식어를 붙인 데에는 분명한 이유가 있습니다.
이번 글에서는 코틀린 컬렉션 API에 녹아있는 함수형 프로그래밍의 철학(Side Effect, 순수 함수)부터, 비슷해 보이지만 완전히 다른 Sequence와 Iterable의 내부 동작 원리, 그리고 빅데이터 처리 패턴과의 연관성까지 이야기 해보겠습니다.
1. 함수형 API: Side Effect의 격리와 선언형 스타일
함수형 프로그래밍의 핵심 중 하나는 부수 효과(Side Effect)를 제어하는 것입니다. 코틀린의 컬렉션 API는 이 철학을 충실히 따릅니다.
Side Effect (부수 효과)와 순수 함수
명령형 프로그래밍에서는 for 문을 돌며 외부 변수의 상태를 변경(Mutation)하는 방식을 주로 사용합니다. 이를 Side Effect라고 합니다. 반면, 코틀린의 함수형 API는 입력받은 데이터를 변경하지 않고(Immutable), 항상 새로운 데이터를 반환하는 방식을 지향합니다.
// [명령형] 외부 변수 result를 계속 변경함 (Side Effect 발생)
val list = listOf(1, 2, 3, 4, 5)
val result = mutableListOf<Int>() // 외부 상태
for (item in list) {
if (item % 2 == 0) {
result.add(item * 2) // 외부 변수 변경
}
}
// [함수형] 외부 상태 변경 없이, 입력과 출력만 존재 (Side Effect 없음)
val resultFunctional = list
.filter { it % 2 == 0 } // 내부적으로 새로운 리스트 생성하여 반환
.map { it * 2 }
이처럼 데이터의 불변성을 유지하면, 멀티스레드 환경에서도 안전하고 예측 가능한 코드를 작성할 수 있습니다.
DSL (Domain Specific Language)
코틀린은 람다 식을 인자로 받는 고차 함수(High-order function)와 수신 객체 지정 람다를 지원합니다. 덕분에 filter, map 등의 연산 체이닝을 마치 문장(DSL)처럼 자연스럽게 읽히도록 작성할 수 있습니다. 이는 "어떻게(How)" 할지보다 "무엇을(What)" 할지에 집중하는 선언형 프로그래밍의 특징을 잘 보여줍니다.
2. 시퀀스(Sequence) vs 이터러블(Iterable)
Iterable과 Sequence는 문법적으로는 거의 동일해 보이지만, 내부 동작 방식은 Eager(Hot)와 Lazy(Cold)로 완전히 다릅니다.
interface Iterable<out T> {
operator fun iterator(): Iterator<T>
}
interface Sequence<out T> {
operator fun iterator(): Iterator<T>
}
Iterable: 단계별 중간 연산 (Eager)
Iterable은 연산 단계마다 중간 결과물(새로운 컬렉션)을 즉시 생성합니다.
public inline fun <T> Iterable<T>.filter(predicate: (T) -> Boolean): List<T> {
return filterTo(ArrayList<T>(), predicate) // 즉시 새로운 ArrayList 생성 및 반환
}
filter를 수행하면 힙 메모리에 새로운 리스트가 생기고, 그 리스트를 대상으로 다시 map을 수행합니다. 데이터가 많을수록 메모리 낭비가 심해질 수 있습니다.
Sequence: 계산은 나중에 (Lazy)
Sequence는 최종 연산(Terminal Operation, 예: toList(), count())이 호출되기 전까지는 아무런 계산도 수행하지 않습니다.
public fun <T> Sequence<T>.filter(predicate: (T) -> Boolean): Sequence<T> {
return FilteringSequence(this, true, predicate) // 연산 안 함. 래퍼 객체만 반환.
}
각 단계는 데이터를 어떻게 처리할지 정의해 둔 일종의 '주문서'일 뿐입니다.
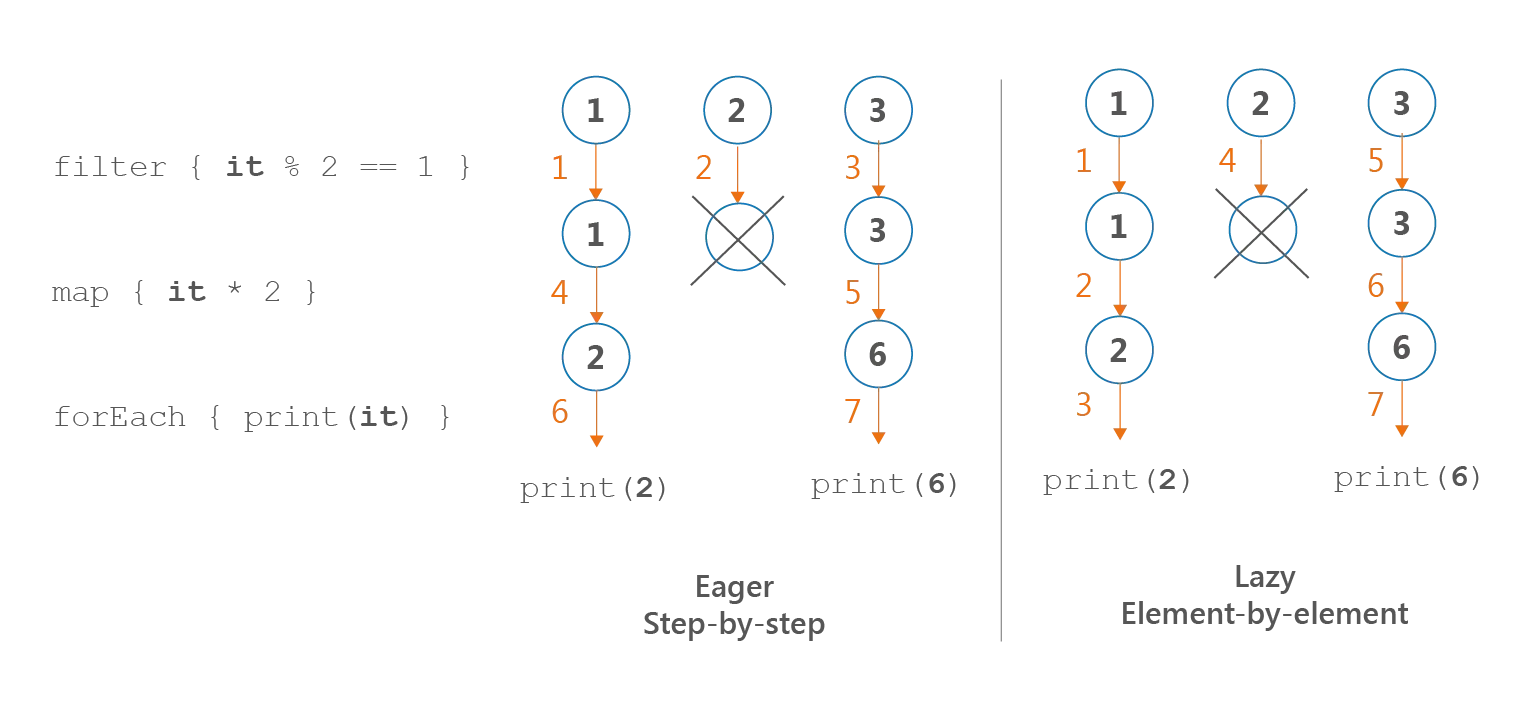
동작 방식의 시각화 (Visualizing Execution)
// [Iterable] 가로 방향 수행 (전체 데이터가 filter -> 전체 데이터가 map...)
listOf(1, 2, 3)
.filter { print("F$it, "); it % 2 == 1 }
.map { print("M$it, "); it * 2 }
.forEach { print("E$it, ") }
// 출력: F1, F2, F3, M1, M3, E2, E6
// [Sequence] 세로 방향 수행 (요소 하나가 filter -> map -> forEach 끝까지 감)
sequenceOf(1, 2, 3)
.filter { print("F$it, "); it % 2 == 1 }
.map { print("M$it, "); it * 2 }
.forEach { print("E$it, ") }
// 출력: F1, M1, E2, F2, F3, M3, E6
3. Sequence의 장점
대부분의 경우 편의상 Iterable을 사용하지만, 다음과 같은 상황에서는 Sequence가 압도적으로 유리합니다.
- 메모리 절약: 중간 리스트(ArrayList)를 생성하지 않으므로 GC 오버헤드를 줄일 수 있습니다.
- Short-circuiting (단락 평가): find, first, take 처럼 전체 데이터를 볼 필요가 없을 때 빠릅니다. (예: 1억 개 중 앞의 5개만 필요하다면, Sequence는 5개를 찾는 즉시 종료됩니다.)
- 무한 스트림 (Infinite Stream): generateSequence를 사용해 끝없는 데이터를 표현하고 필요한 만큼만 가져다 쓸 수 있습니다.
4. Sequence Deep Dive: 내부 구현의 비밀
Sequence는 어떻게 Lazy하게 동작할까요? 두 가지 핵심 메커니즘이 있습니다.
비밀 1: 데코레이터 패턴 (Decorator Pattern)

sequence.map { ... }을 호출한다고 해서 연산이 수행되지 않습니다. 단지 기존 시퀀스를 감싸는 새로운 껍데기(객체)를 만들 뿐입니다.
- sequenceOf(1, 2, 3): 기본 Sequence
- .filter { ... }: 기본 시퀀스를 감싸는 FilteringSequence 객체
- .map { ... }: 필터 시퀀스를 감싸는 TransformingSequence 객체
최종 연산(toList, forEach)이 호출되어 "데이터 줘!"(iterator().next())라고 외쳐야, 가장 바깥쪽 껍데기부터 안쪽으로 요청이 전달되며 데이터가 흐르기 시작합니다.
비밀 2: 코루틴과 State Machine (yield)
sequence { } 빌더는 가장 강력한 시퀀스 생성 방법입니다. 이를 사용하면 명령형 코드 스타일로 시퀀스를 정의할 수 있는데, 내부적으로는 상태 머신(State Machine)으로 동작합니다.
val fibonacci = sequence {
var a = 0
var b = 1
yield(1) // 값 배출 후 일시 중단 (Suspend)
while (true) {
yield(a + b) // 값 배출 후 일시 중단
val tmp = a + b
a = b
b = tmp
}
}
Yield의 동작 원리: yield는 스레드를 차단(Block)하는 것이 아니라, 함수의 실행을 잠시 멈춤(Suspend) 상태로 둡니다. 다음 값이 필요해지면 멈췄던 그 라인, 그 변수 상태 그대로 다시 실행을 재개(Resume)합니다.
컴파일러는 이 코드를 SequenceBuilderIterator를 상속받는 클래스로 변환하고, label 변수를 통해 실행 위치를 제어합니다.
// 컴파일러가 생성한 코드의 단순화된 형태
class MySequenceStateMachine : SequenceBuilderIterator<Int>() {
var label = 0 // 현재 실행 위치 기억
override fun invokeSuspend(result: Result<Any?>) {
when (label) {
0 -> {
label = 1
yield(1) // 값 반환 후 return (함수 종료 효과)
}
1 -> {
// 이전에 멈춘 곳(yield 다음)부터 로직 재개
label = 2
yield(nextValue)
}
// ...
}
}
}
핵심은 스레드를 쓰지 않고 변수 하나(label)로 실행 위치를 기억하기 때문에 매우 가볍다는 점입니다. 이 메커니즘은 코틀린 코루틴(Coroutines)과 Flow의 기반이 됩니다.
5. Sequence와 Reduce: 빅데이터 연산의 축소판
Sequence와 reduce(또는 fold)의 조합은 하둡(Hadoop)과 같은 빅데이터 프레임워크의 MapReduce 패턴과 많이 닮아 있습니다.
- Map: 데이터를 변환 (Sequence의 map)
- Filter: 불필요한 데이터 제거 (Sequence의 filter)
- Reduce: 데이터를 하나의 결과로 집계 (Sequence의 reduce)
빅데이터 프레임워크가 거대한 데이터를 분산 처리한다면, 코틀린의 Sequence는 메모리 내부의 데이터를 파이프라인을 통해 효율적으로 흘려보내며 처리합니다.
data class Transaction(val id: Int, val amount: Int, val type: String)
// 입금(DEPOSIT)된 총액 구하기 (MapReduce 패턴)
val totalDeposit = transactions
.filter { it.type == "DEPOSIT" } // [Filter]
.map { it.amount } // [Map]
.reduce { acc, amount -> // [Reduce]
acc + amount
}
6. Java Stream API vs Kotlin Sequence
자바 8의 Stream API와 코틀린의 Sequence는 모두 지연 연산(Lazy Evaluation)을 수행한다는 공통점이 있지만, 설계 목적과 특징에서 차이가 있습니다.
- 병렬 처리 (Parallelism):
- Java Stream: 태생부터 병렬 처리를 위해 설계되었습니다. .parallel()을 통해 쉽게 병렬화가 가능합니다.
- Kotlin Sequence: 순차 처리(Sequential)만 지원합니다. 코틀린은 병렬 스트림의 복잡성보다는, 필요시 코루틴 등을 활용하는 방식을 권장합니다.
- 재사용성 (Reusability):
- Java Stream: 일회용입니다. 한 번 최종 연산을 수행하면 스트림이 닫혀 재사용할 수 없습니다.
- Kotlin Sequence: Iterable 기반의 시퀀스(예: list.asSequence())는 여러 번 순회(재사용)가 가능합니다.
- 성능 오버헤드:
- Java Stream: 병렬 처리를 위한 내부 구조가 다소 무겁습니다.
- Kotlin Sequence: Iterator를 감싼 단순한 래퍼(Wrapper)로, 매우 가볍습니다.
결론: 복잡한 수학 연산을 대규모 병렬로 처리해야 하는 특수한 상황이 아니라면, 코틀린 프로젝트에서는 Kotlin Sequence를 사용하는 것이 문법적으로 더 깔끔하고(확장 함수), 성능상으로도 효율적입니다.
참고 자료:
- Kotlin Sequences: An Illustrated Guide (강력 추천 시리즈)
'개발' 카테고리의 다른 글
| [Kotlin] Null을 대하는 자세: 꼬리표(Nullable)와 세계관의 분리 (1) | 2025.12.10 |
|---|---|
| 람다에 대해서 알아보자 - 1편 (탄생배경, 변수캡쳐, 함수타입) (0) | 2025.11.26 |
| 싱글톤 패턴 (0) | 2025.03.30 |
| Index는 왜 B-Tree를 사용하나 (0) | 2025.03.16 |
| Ajax에 대해서 알아보자 (0) | 2025.03.02 |
